未来智能交互核心,人工智能的主战场——语义识别如今发展如何?

什么是语义识别
语义识别是自然语言处理(NLP)技术的重要组成部分之一,语义识别的核心除了理解文本词汇的含义,还要理解这个词语在语句、篇章中所代表的意思,这意味着语义识别从技术上要做到:文本、词汇、句法、词法、篇章(段落)层面的语义分析和歧义消除,以及对应的含义重组,以达到识别本身的目的。
语义识别可以分为三层:
1.应用层:
包括行业应用和智能语音交互系统/技术应用。
2.NLP技术层:
包括以语言学、计算机语言等学科为背景的,对自然语言进行词语解析、信息抽取、时间因果、情绪判断等等技术处理,最终达到让计算机“懂”人类的语言的自然语言认知,以及把计算机数据转化为自然语言的自然语言生成。
• 词语解析与信息抽取:包括分词、词性标注、命名实体识别和词义消歧,从给定文本中抽取重要的信息。
• 句法解析与语篇理解:对篇章结构的一系列连续的子句、句子和语段间一定层次结构和语义关系的分析,包括时间、事件、因果关系等,甚至于文本所携带的情绪识别。
• 自然语言生成:从结构化数据中以可读地方式自动生成文本的过程。包括三个阶段:文本规划(完成结构化数据中基础内容的规划)、语句规划(从结构化数据中组合语句,来表达信息流)、实现(产生语法通顺的语句来表达文)。
3.底层数据层:词典、数据集、语料库、知识图谱,以及外部世界常识性知识等都是语义识别算法模型的基础。
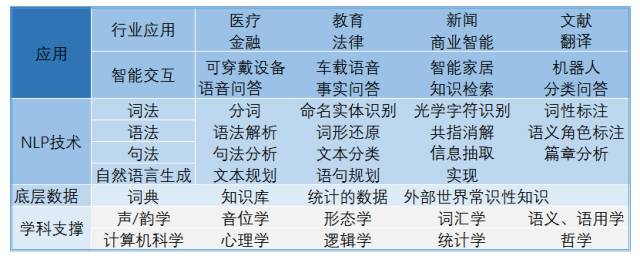
语言本身词性、词性、词义、表意、组成逻辑复杂等性质,决定了语义识别的难度。因而语义识别技术也涉及语言学、计算机语言、数学、统计学、哲学、生物学等诸多广泛的学科支撑:
• 音韵学 :指代语言中发音的系统化组织。
• 词态学:研究单词构成以及相互之间的关系。
• 句法学:给定文本的哪部分是语法正确的
• 语义学:给定文本的含义是什么?
• 语用学:文本的目的是什么?
语义识别应用场景
语义识别技术可以分析网页、文件、邮件、音频、论坛、社交媒体中的大量数据,应用领域广泛,既可以直接应用于医疗、教育、金融等行业。也可以通过技术接口应用于所有智能语音交互场景,如智能家居、车载语音、可穿戴设备、VR、机器人等,从交互的方式上,也可以分为:事实问答、知识检索、分类问题等。智能语音交互被看做未来人工智能技术中最值得期待的应用场景。
医疗+:
教育+:
金融+:
法律+:
新闻/文献+:
智能商业+:
翻译+:
未来,基于深度学习的翻译技术将更多的应用在会话、同声翻译、文本翻译等多种场景。

语义识别环境背景分析
语音识别、语义识别是自然语言处理最重要的两项技术,且联系紧密,在上述语义识别的广泛应用场景中,常常是语音、语义相互嵌套,共同作用的结果,大多数研究语义识别的公司也涉及到语音识别技术的研究,因而下述的分析中,涉及数据方面,我们更多的是放在“自然语言处理”层面来讨论的。
自然语言处理作为一项重要的人工智能技术之一,成为 2017年最炙手可热的领域,在整体上离不开政策上的支持,技术上的进展,市场应用的极高价值,资本投资等多方面的共同作用。
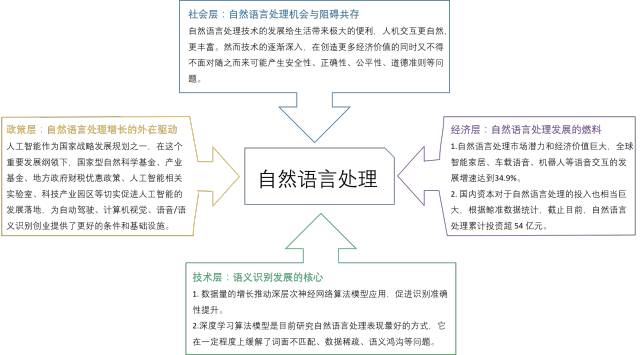
政策层面:
政策引导是语义识别增长的外在驱动
人工智能作为国家战略发展规划之一,足见其重要性,在这个政策的纲领下,国家型自然科学基金、产业基金、地方政府财税优惠政策、人工智能相关实验室、科技产业园区等切实促进人工智能的发展落地,为自动驾驶、计算机视觉、语音/语义识别创业提供了更好的条件和基础设施。
经济层面:

经济价值是语义识别发展的燃料
一方面,自然语言处理应用场景广泛,市场潜力和经济价值巨大, 的数据显示,2017-2024这七年,智能语音交互的全球市场,每年增长率将达到34.9%。据估算,2024年的全球市场规模,将达到720亿元。
另一方面,国内资本对于自然语言处理的投入也相当巨大,根据鲸准App数据统计,截止目前,自然语言处理已披露融资总额累计超 54 亿元。
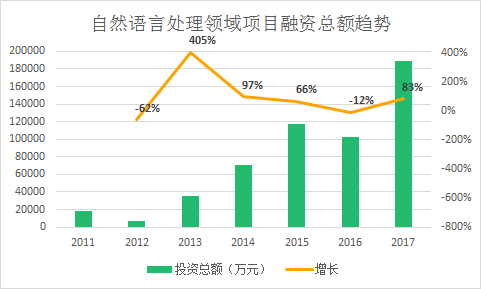
自2015年以来,资本每年在自然语言处理领域的投资达到10亿元以上,2017年投资总额达到了18亿,从趋势上,近几年资本对于自然语言处理创业公司的关注度不断上升,资本投入也在加大(2015年5起、2016年12起、2017年1起未披露金额投资事件未计入下表统计)。
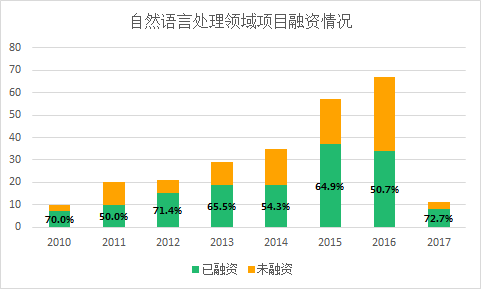
此外,在创业获投率上,自然语言处理相关公司的获投率达到惊人的50%以上。
社会层面:
机遇与阻碍共存
自然语言处理技术的发展给生活带来极大的便利,人机交互更自然,更丰富。然而技术的逐渐深入,在创造更多经济价值的同时又不得不面对随之而来可能产生安全性、正确性、公平性、道德准则等问题。
技术层面:
技术进步语义识别发展的核心
1. 数据量。
经过互联网、社交网络、行业信息化、云存储的发展,很多地方就积累了足够量的数据。当数据量不足时,自然语言处理还只能进行浅层模型分析,准确性上受到限制;当数据量增大,运用RNN、CNN为代表的神经网络深度算法模型对数据进行更复杂、精确的建模,从而使语言、语义的识别达到更好的效果。
2. 算法模型。
语义识别的实现离不开NLP语言处理任务系统,随着更大语料库的建设和语料库语言学的崛起,基于密集向量表征的神经网络在多种NLP任务上的应用获得优秀成果。

尽管深度学习算法模型并不是自然语言处理最佳的方式,但确是目前研究自然语言处理表现最好的方式,它在一定程度上缓解了词面不匹配、数据稀疏、语义鸿沟等问题。
自然语言处理创业数据与投资关注动态
1.自然语言处理创业数据
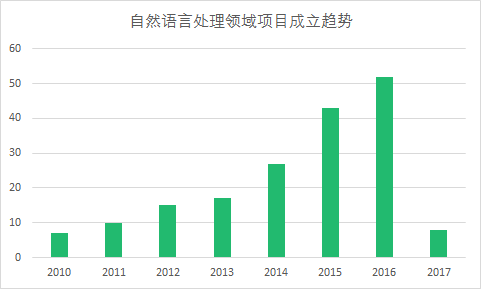
根据鲸准App数据统计,自2010年起,国内有关于自然语言处理的新创公司有179家,分别在2014年、2015年和2016年呈现公司成立激增的状态,而2017年公司创立有明显的下滑状态,分析原因,一方面如思必驰、云之声、助理来也等先发成立的初创公司在时间、技术、融资方面已经取得不小的优势,另一方面,在新技术应用场景开发、技术人才储备上有一个断档期。
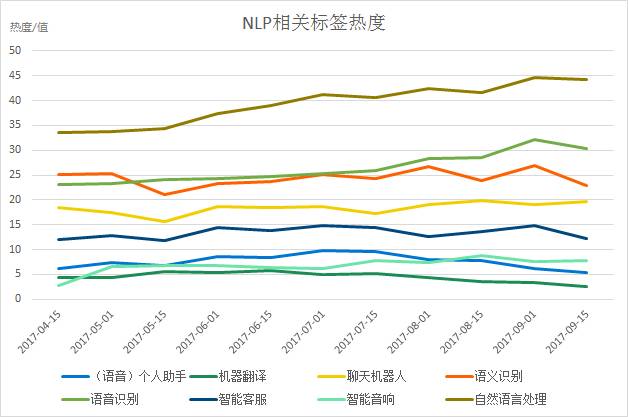
2.自然语言处理相关标签热度
鲸准App近5个月的标签关注热度显示,自然语言处理整体关注度持续增长,其中语音识别关注度从7月以来增长明显,而机器翻译、语音个人助手的关注热度较之前有所下滑,其余语义识别、聊天机器人、智能客服、智能音响呈现稳定的波动和持续的关注状态。
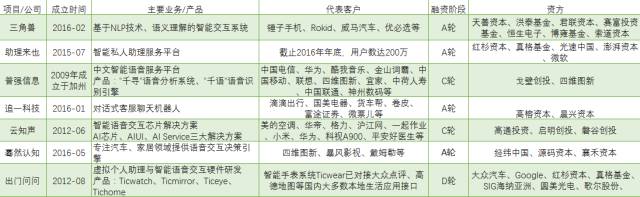
3.科技巨头相关进展
虚拟助理,智能音箱,AI翻译……科技巨头今年在语音、语义识别领域有不少大进展。
苹果Siri,谷歌,微软小娜,三星 S8也在今年发布了自己的Bixby智能助理,京东、阿里巴巴、百度、联想、小米、出门问问和喜马拉雅等公司都相继发布和更新迭代了自己的智能音箱产品,抢占家庭场景入口;包括、、微软、百度、腾讯、搜狗在内的各大技术巨头却在不遗余力地推进深度学习在机器翻译领域的研发和应用……

4.自然语言处理创业代表厂商
国内最早的自然语言处理创业公司在经过几年的发展,已经在很多领域获得比较大的成果,各大厂商在识别技术上体现出来的差异性并不是太大,值得注意的是,语音识别、语义识别技术应该更加重视场景的垂直,在这方面,各大厂商各有定位和建树,因而,精准App数据中心只列举展示了数据库中所受关注度较高的项目(排名不分先后),如需了解更多优质早期项目,请下载关注“鲸准App”。
- END -
文|李园园
Email:@.com

